This article will help you explore the main functionalities of distributed file system and show how it differs from the traditional \ files systems that we currently have on our computers. Try to understand the need to have a distributed file system and how this can empower Big Data concept.
Taha Mahmoud introduces you to the concept of Distributed file system. The article touches on The concept of DFS, its advantages, uses and concerns.
Key Concepts
Distributed file system is used to manage files and data blocks across different clusters and racks. The will enhance fault tolerance and access concurrency by replicating data blocks on different clusters to ensure fault tolerance and parallelism.
By reading this article you will be :
- Able to differentiate between file system (FS) and distributed file system (DFS)
- Understand how DFS works?
- Explore the advantages of DFS?
What is File System (FS)?
The first storage mechanism used by computers to store data was punch cards. Each group of related punch cards (Punch cards related to same program) used to be stored into a file; and files were stored in file cabinets. This is very similar to what we do nowadays to archive papers in government intuitions who still use paper work on daily basis. This is where the word “File System” (FS) comes from. The computer systems evolved; but the concept remains the same. Instead of storing information on punch cards; we can now store information / data in a digital format on a digital storage devices such as hard disk, flash drive…etc. Related data are still categorized as files; related groups of files are stored in folders. Each file has a name, extension and icon. The file name gives an indication about the content it has while file extension indicates the type of information stored in that file. for example; EXE extension refers to executable files, TXT refers to text files…etc.
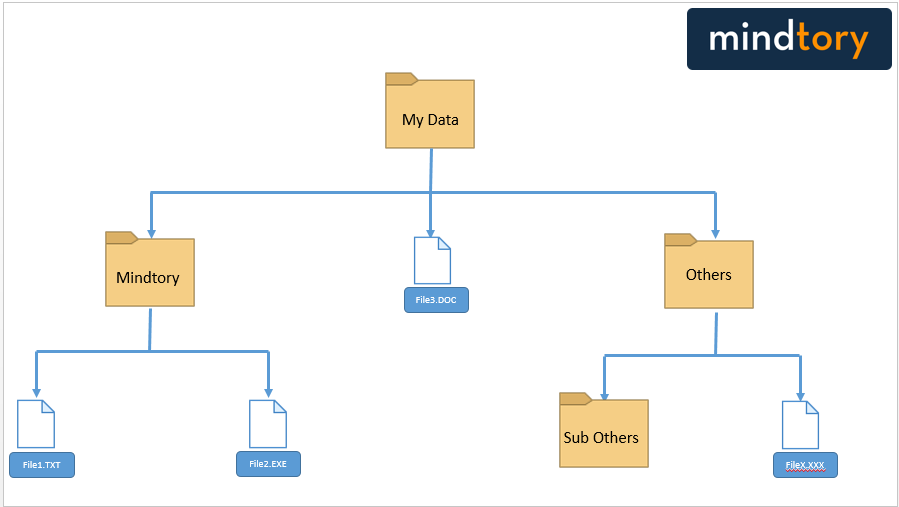 Figure # 1: Example to file system – FS
Figure # 1: Example to file system – FS
File management system is used by the operating system to access the files and folders stored in a computer or any external storage devices. Imagine file management system as a big dictionary that contains information about file names, locations and types. File management system is capable of handling files within one computer or a cluster. But what if we have many? So here comes DFS
What is Distributed file system (DFS)?
In Big Data, we deal with multiple clusters (computers) often. One of the main advantages of Big Data which is that it goes beyond the capabilities of one single super powerful server with extremely high computing power. The whole idea of Big Data is to distribute data across multiple clusters and to make use of computing power of each cluster (node) to process information.
Distributed file system is a system that can handle accessing data across multiple clusters (nodes). In the next section we will learn more about how it works?
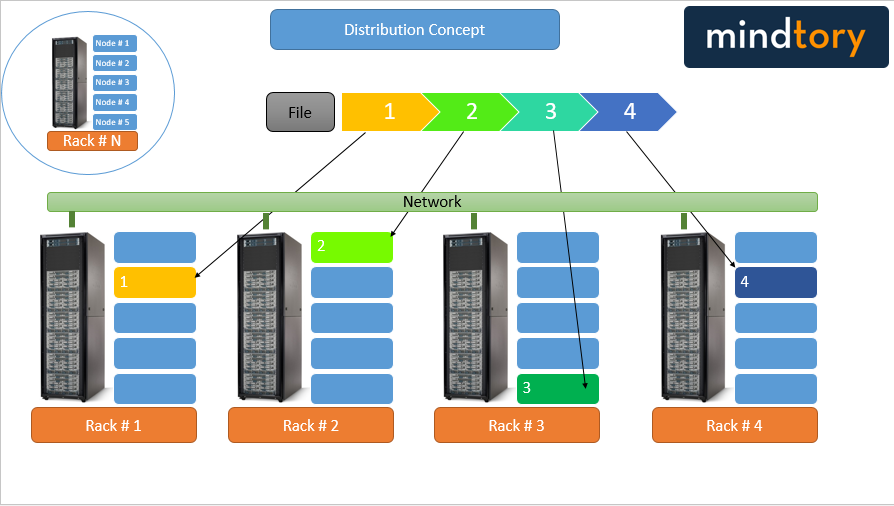
How Distributed file system (DFS) works?
Distributed file system works as follows:
- Distribution: Distribute blocks of data sets across multiple nodes. Each node has its own computing power; which gives the ability of DFS to parallel processing data blocks.
- Replication: Distributed file system will also replicate data blocks on different clusters by copy the same pieces of information into multiple clusters on different racks. This will help to achieve the following:
- Fault Tolerance: recover data block in case of cluster failure or Rack failure.
- High Concurrency: avail same piece of data to be processed by multiple clients at the same time. It is done using the computation power of each node to parallel process data blocks.
The following graph shows how data replication concept works:
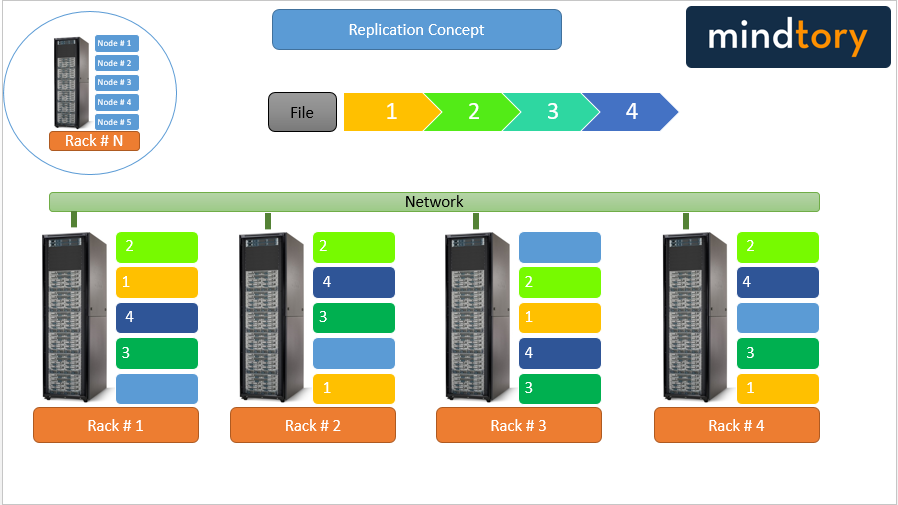 The following figure shows how fault tolerance can be achieved by data replication:
The following figure shows how fault tolerance can be achieved by data replication:
Data replication is a good way to achieve fault tolerance and high concurrency; but its very hard to maintain frequent changes. Assume that someone changed a data block on one cluster; these changes need to be updated on all data replica of this block.
What are the Advantages of Distributed File System (DFS)?
Distributed file system provides the following main advantages:
- Scalability: You can scale up your infrastructure by adding more racks or clusters to your system.
- Fault Tolerance: Data replication will help to achieve fault tolerance in the following cases:
- Cluster is down
- Rack is down
- Rack is disconnected from the network.
- Job failure or restart.
- High Concurrency: utilize the compute power of each node to handle multiple client requests (in a parallel way) at the same time.
The following figure illustrates the main concept of high concurrency and how it can be achieved by data replication on multiple clusters.
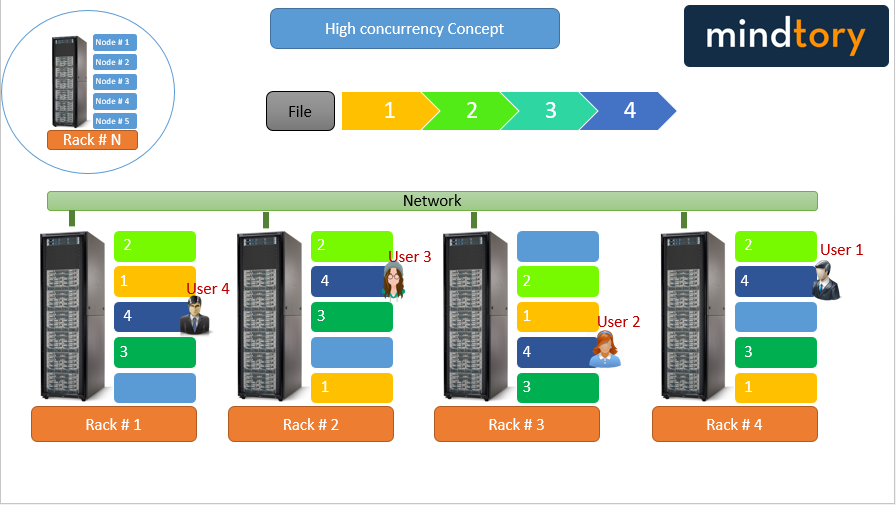
Conclusion
Distributed file system is the new evolved version of file system which is capable of handling information distributed across many clusters. Hadoop distributed file system (HDFS) is one of the most common known implementation of DFS; although there are many other implementations like: Ceph, GlusterFS,…etc. Subsicribe with us to be notified about our future article releases which will covers topics like:
- Future of DFS
- Brief introduction about DFS algorithm
- Introduction to HDFS
References
- Ceph: http://ceph.newdream.net/
- GlusterFS: http://www.gluster.org/
- HDFS: http://hadoop.apache.org/hdfs/
- HekaFS: http://www.hekafs.org/
- OrangeFS: http://www.orangefs.org/and http://www.pvfs.org/
- KosmosFS: http://code.google.com/p/kosmosfs/
- MogileFS: http://danga.com/mogilefs/
- Swift (OpenStack Storage): http://www.openstack.org/project…
- FAST’11 proceedings: http://www.usenix.org/events/fas…
1 Comment
Comments are closed.

Great and usefull articale